SCB MBON Data Management Overview
Processing Pipeline
For planning and tracking progress, SCB MBON's data workflows are arranged by stage. Processing stages, "Raw", "Cleaned" and "Standarized metadata", are based on the generic workflow created by the MBON data managers (MBON DMAC, 2016), and shown on the left in Figure 1. These stages generally refer to the amount of formal metadata available, and the degree to which data and metadata have been prepared for inclusion in a pubic repository. SCB MBON data are currently published as "Cleaned". For some tables and their attributes, metadata will advance to "Standardized" after a) our table attributes have been mapped to appropriate external dictionaries (e.g., Darwin Core), and b) the EML specification handles semantic information. These conditions are both expected to be met during 2017 (e.g., the release of EML 2.2).
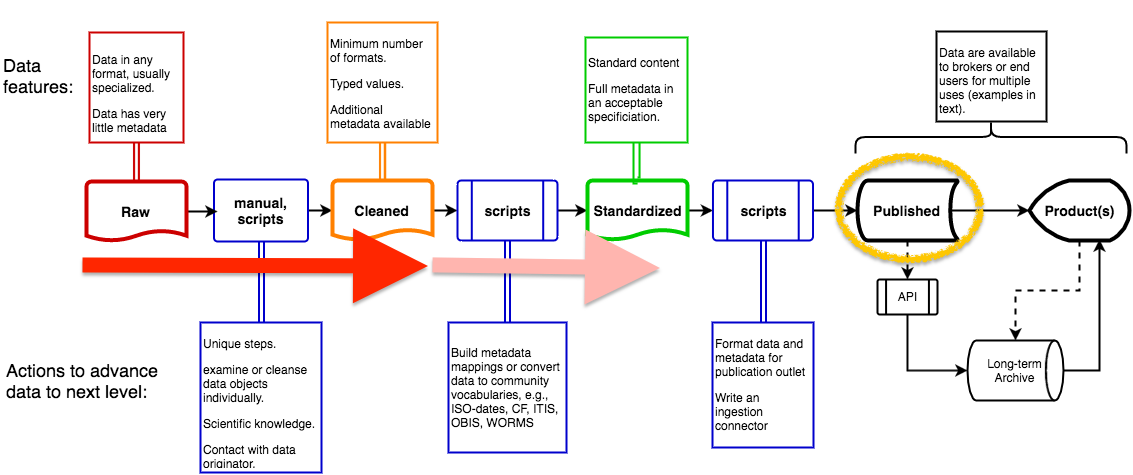
Figure 1. Generic MBON data processing workflow. SCB MBON currently are "Cleaned" with "Standardized" expected for some tables/attributes by the end of 2017 (red arrows). The repository is indicated by gold oval. From: MBON DMAC. 2016. Data management alignment, Workshop report.
Repositories Submissions
SCB MBON contributes all cleaned (curated) datasets to a public repository which supports DOIs, metadata and data immutability, and dataset versioning. We reduce redundant contributions by using federated systems that link multiple repositories a priori. The repository of the Environmental Data Initiative (EDI, https://environmentaldatainitiative.org) is a member node of the DataONE federation (https://dataone.org), and so contributing there ensures that SCB MBON data can be found alongside data from other DataONE member nodes (with all available through a single API). NODC (NCEI division) is already a DataONE member node and AOOS and GCOOS are developing member node capabililty. Further, DataONE already supports Darwin Core, and is exploring indexing by GBIF, two features that will facilitate data flow to OBIS.
SCB MBON maintains a catalog of its datasets in public repositories: SCB MBON Data catalog.
Dataset Packaging
SCB MBON datasets are classified according to their metadata needs (A, B or C). Because the EDI repository and DataONE support versioning, metadata and data can be enhanced in future revisions.
- A. Full metadata:
- Two types of datasets receive full (entity-level) metadata per the practices of LTER Network and EDI.
- Data collected de novo by the project. Data are owned by SCB MBON, and SCB MBON controls all metadata.
- examples
- abundance generated by Bisque imagery analysis
environmental DNA
- Curated or reformatted external data. These are datasets for which SCB MBON is acting as a "broker". Many aspects of metadata are determined by the contributor: Data ownership, intellectual rights (although we encourage adoption of SCB MBON practices for ownership and licensing), collection methods, and processing code (where appropriate). If data were obtained from a repository or web service, SCB MBON includes that link as is possible, e.g. as data source under methods or provenance.
- examples
- CalCOFI Fish Larvae abundance
Gray Whale Counts
- Data collected de novo by the project. Data are owned by SCB MBON, and SCB MBON controls all metadata.
- B. Full metadata plus provenance:
- Data products that result from integration of other datasets. These may be biodiversity indices or other integrations, e.g., combined abundances from several surveys. These products receive the highest level of metadata content, full metadata (per LTER practices), plus provenance information (e.g., data sources, processing parameters and software) to ensure results are easy to interpret and trustworthy. Provenance via annotation is planned to use DataONE annotations (as these systems mature); currently provenance is included as text metadata under "Methods".
- examples
- Biodiversity indices
Integrated kelp forest fish and benthic cover
- C. Cited exogenous data:
- Source data that are already publicly available, and curated and managed by a non-SCB MBON group will be cited and linked in our catalog. If necessary, SCB MBON will create citation-level metadata to external resources, i.e., metadata adequate to produce a data citation that is analogous to a paper citation and consistent with ESIP guidelines. These include original creator, title, date, publisher, system and ID. A URL will be included if no persistent ID is available.
- examples
- Dataset of Giant Kelp biomass, produced by the Santa Barbara Coastal Long Term Ecological Research (LTER) project
External Resources and References
- EML Project
- https://knb.ecoinformatics.org/#external//emlparser/docs/index.html
- https://github.com/NCEAS/eml
- ESIP - Interagency Data Stewardship/Citations/provider_guidelines
- https://wiki.esipfed.org/index.php/Interagency_Data_Stewardship/Citations/provider_guidelines
- MBON DMAC. 2016. Data management alignment, Workshop report
- https://workspace.ioos.us/group/230656/project/1804166/folder/1818398/products>